ブログを書いていると、自分の記事の順位が気になったりします。果たして自分の記事はGoogleにどう評価されているのか? 気になりますよね。そこで私はGoogleの検索順位を毎日自動で取得するプログラムを作成してみました。
これまで使っていた順位検索ツール
これまで私はGRCと言う順位検索ツールを使用しておりました。こちらは無料版があり、誰でも簡単に利用ができます。しかも、YahooやGoogle、Beingの3つの検索エンジンの結果を表示してくれます。
順位を簡単に迅速に3つの検索エンジンまとめてチェックできて、ある意味凄いです。どうやって実現しているのか興味あります。
ただし、無料版には制限があり検索できるKeywordsは10件までです。制限を超えて使用するには有料バージョンが必要となります。月額払いですが、約500円から利用できます。ただ、CSVファイルにも順位を保存したりしたい場合はアルティメット版で2,475円/月となり、なかなかSubscritionには躊躇します。
検索順位の結果を自動取得してCSV化したい
そこで、私はGoogleだけで良いので自作する事でCSVファイルにも自動で毎日順位を残せるようにしたいと考えました。
その為に、まず最初に思いつくのはGoogleのAPIサービスのCustom Search APIです。こちらはDocumentを読むと1日100回まで無料で検索が可能なREST APIです。検索結果もJSON形式で取得できるので便利です。プログラム的に自動化してCSVファイルに記録して分析するのに使えるかなと思いました。
私のブログページは現在ページ数も多くないので、1日100検索でも十分です。例えば40位までの順位を検索するなら、100/4=25 で、最大25のkeywordsの検索が可能です。(一回の検索には上位10件までの検索しかできず、20位以降はオフセットのパラメターを付けて20位から29位までの順位検索をします。したがって40位まで調べたければ、1キーワードにつき4回の検索のAPIリクエストが必要です)
問題点:Google Custom Searchの結果はなぜかWebで検索した結果と違う
個人的にはこれでもいいかなと思ったのですが、実際にAPIをつかったCustom Searchをしてみると、WebブラウザーでGoogleで検索したときの結果と違います。詳しい理由はわかりませんが、Webの検索結果と違うのは致命的な欠陥です。
そこで、Seleniumを使用してBrowserでの一連のオペレーションをプログラムして取得する事を考えたのですが、ページ送りとかして次の順位を得たり、結果の取得の為のclassやHTMLタグの確認とかプログラムが複雑になりそうだったので、どうしたものかと悩んでいたところ、Beatifulsoupを使用して順位を検索できると言う記事を見つけたので、早速参考にさせていただきました。
結論 簡単にプログラムできました
結論から言うと、簡単に無料の検索自動化ができました。しかも、ページネーションみたいなことも必要なく、一回の検索時に検索の取得したい数を指定できます。私の場合は40位までを検索したいので、一回のクエリーで40位までの結果を取得しています。Pythonで書いてます。私はPerlが得意なシニアのエンジニアですが、Pythonも便利だと感じます。でもやっぱりPerlが好きですが・・・・。(笑
PythonのライブラリーのBeatifulsoupがお勧め
PythonでWebスクレイピングのBeatifulsoupを使用します。 BeatifulsoupはHTMLをパースして必要な部分だけを取り出してくれるPythonのライブラリです。そして、検索には以下のURLにアクセスするだけでした。
https://www.google.co.jp/search?num=40&q=<keywords>例えば、”屋根裏収納スペースDIY”という検索で上位40件の結果を取得したい場合は、以下のURLの結果をBeatuifulsoupでWebScrapingするだけです。
https://www.google.co.jp/search?num=40&q=屋根裏収納スペースDIYそれを以下のコードで処理してCSV化します。
コード例
メインの処理がこちらです。
keywords_csv_file_number = sys.argv[1]
blog_titles = './blog-search-keywords-'+keywords_csv_file_number+'.csv'
rank_log = './blog-rank-log.csv'
with open(rank_log, 'a',newline='',encoding='utf-8') as result_log:
writer = csv.writer(result_log)
with open(blog_titles, 'r',encoding='utf-8') as f:
csv_f = csv.DictReader(f, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
for row in csv_f:
rank_detail = googleRankSearch(row['keywords'])
if rank_detail[3] == 0:
rank_detail[4] = row['title']
rank_detail[5] = row['url']
# CSV書き込み
writer.writerow(rank_detail)
# 人間のように振る舞うためのインターバル 10秒
time.sleep(10)
簡単に説明すると、上記のコードは最初に検索するkeywordのリストされたCSVファイル( ./blog-search-keywords-X.csv)を読み込みます。このXの部分はこのプログラムがWindowsのタスクスケジューラーから呼ばれるときに渡される数値で、私の場合、1~3あります。実は、これが大切で、なぜKeywordの検索を3回に分けているかと言うと、一気に大量のキーワード検索を行うとGoogleから検索を一定時間サスペンドされてしまうからです。
そこで、私は約50件の検索キーワードを、3つのCSVファイルに分けて30分間隔で検索して、結果の順をCSVファイルに追記していく方法を取りました。これでGoogleからの検索ペナルティーはくらいません。
さて、次に検索順位の結果を書き込むCSVファイル( blog-rank-log.csv )を追記モードでオープンします。そして、ループしながら、検索キーワードをREST APIで実行して結果を取得しています。以下が、そのREST APIの処理部分のFunctionです。
def googleRankSearch(keywords):
d_today = datetime.date.today()
t_now = datetime.datetime.now().time()
now_time=str(t_now).split('.')
# 40位までcheck
url = 'https://www.google.co.jp/search?num=40' + '&q=' + keywords
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:65.0) Gecko/20100101 Firefox/65.0"
headers = {"User-Agent": user_agent, 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'}
# Google検索を実施
source=requests.get(url, headers=headers).text
# Google検索の結果からタイトルとURLを抽出
soup = BeautifulSoup(source, 'lxml')
#search_div = soup.find_all(class_='rc')
search_div = soup.find_all(class_='yuRUbf')
#search_div = soup.find_all(class_='fl')
i=1
# 抽出したタイトルとURLを表示
for result in search_div: # loop result list
title = result.h3.string
page_url = result.a.get('href')
if 'xxx.yyy.zzz' in page_url:
return [d_today,now_time[0],keywords,i,title,page_url]
else:
i=i+1
return [d_today,now_time[0],keywords,0,'na','na']
上記の、xxx.yyy.zzz のところに自分のブログのドメインを入れると、検索結果の中から自分のドメインが含まれる順位を取得できます。私はそこに”diy-hs.com” を指定しています。
そして、この結果をCSVに書き込むときには、日付とキーワードと順位、タイトルとURLを保存しています。もし、40位までに見つからない場合は、日付とキーワードと、順位は0位としてReturnしています。
これで無事に結果がCSVに保存され続けていきます。私の場合、早朝に立ち上げっぱなしのWindowsOSのノートパソコンから、タスクスケジューラーで30分間隔で約50件のキーワードを3分割してGoogleの検索のエンドポイントにリクエストして結果を取得しています。
タスクスケジューラーの使い方がわからないという方、結構簡単です。ネットで検索すると詳しく説明してくれているサイトがたくさんあるので探してみて下さい。
さて私の場合、40位までの順位をチェックしていますが、REST APIのパラメターでnum=XXの部分で変更が可能と思います。最大値とかはペナルティー食らうのが嫌なので怖くて試していません。(笑)
あと、言うまでもありませんが、必要なImportは以下です。
import requests
from bs4 import BeautifulSoup
import json
import csv
import time
import datetime
import sys毎日自動的にCSVが作成されるので便利です。
検索順位結果のグラフ化
そして私はTableauでグラフ化しています。Tableauはとても簡単にデータを色んな角度からビジュアル化できるのでとても気に入ってます。そのグラフ化がこちら。1月6日から使用開始して順調です。
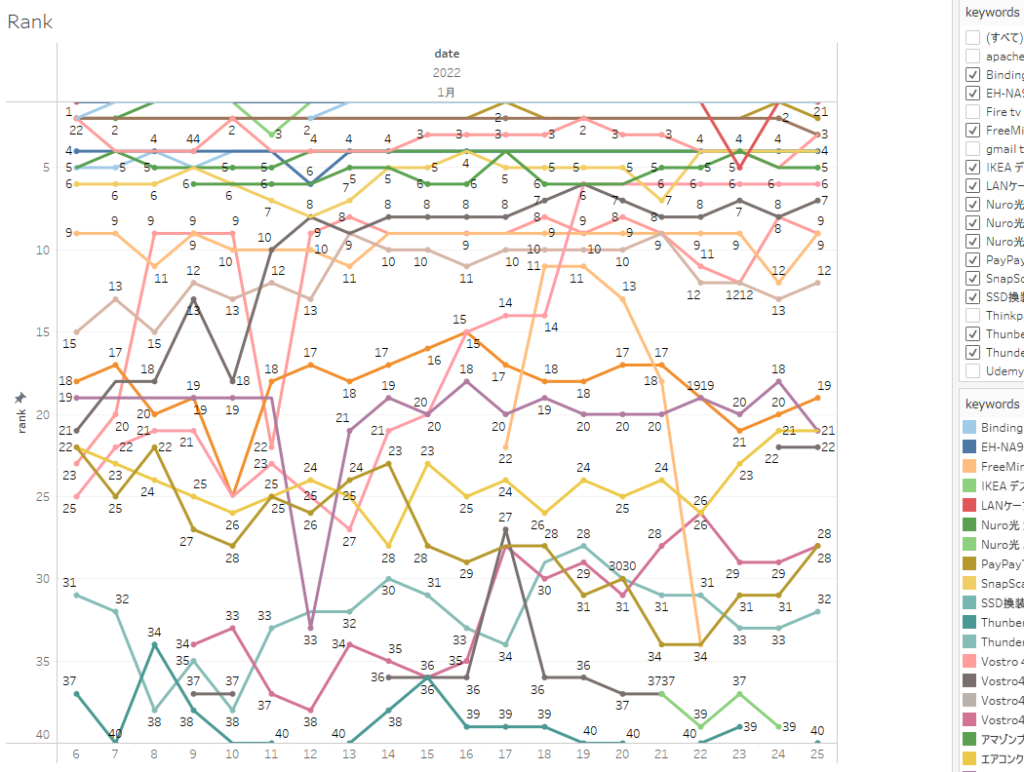
グラフ化には、Tableauを使わなくてもD3.jsのような無料のJavascriptフレームワークを利用してWeb化するのも良いかと思います。そうすればいつでもどこからでもブラウザー経由で順位のグラフを参照できますね。ただ、D3.jsはちょっと勉強が必要です。私はUdemyのこのコースでD3を学びましたがとても良かったので、D3.jsを学習したい方にはお勧めです。英語コースですが、サンプルを見ながら進めるので、とても分かりやすかったです。Javascriptが好きな方はD3.jsで楽勝かも?私は非同期プログラミングは苦手なので、グラフ化はもっぱらTableauです。
講師の人。

Mastering data visualization in D3.js
以上です。
他にもTableauやPythonについて学びたい場合は、Udemyのコースが結構お勧めです。
Google検索順位の自動取得を考えている方の参考になれば幸いです。
最後までお読みいただきありがとうございました。
投稿者プロフィール

-
”なんでも自分でやってみる” をテーマに、ブログを書いてます。素人には無理と思う様な事も、実際にやってみるとあっさりと出来たりする事もあります。失敗もありますが、失敗する事で経験となり、次は少し上達したりします。それが楽しいです。そんなDIYの情報を発信して行けたらと思ってます。仕事はAIやクラウド関連を担当してます。そんな訳でプログラミングやシステム構築も趣味と実益を兼ねてDIYを楽しんでます。ギターはもともとクラシックギターを学び、インストルメンタル専門でしたが、高校生の頃にテレビでみた卒業の映画でPaul Simonの曲に憧れて、それ以降いろんなジャンルの弾き語りも楽しんでます。S&Gの曲なら楽譜なしで弾けます。^^; また最近は独学でピアノも始めました。すでに4曲ほどレパートリーがあります。Twitterの方でも発信していますので、ぜひフォロー下さい。
(Amazonのアソシエイトとして、当サイト(diy-hs.com)は適格販売により収入を得ています。)
最新の投稿
 園芸DIY2026年7月5日チュウゴクアミガサハゴロモ対策に粘着シートを試してみた
園芸DIY2026年7月5日チュウゴクアミガサハゴロモ対策に粘着シートを試してみた 他DIY2026年3月31日アラジンのストーブ窓交換 DIY
他DIY2026年3月31日アラジンのストーブ窓交換 DIY 他DIY2026年3月21日Technics PX105 再利用 DIY
他DIY2026年3月21日Technics PX105 再利用 DIY DIY全般2026年2月8日Honda CB1300 Final Edition タンクの傷修理 DIY
DIY全般2026年2月8日Honda CB1300 Final Edition タンクの傷修理 DIY



コメント